几乎所有的编程语言都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数组。在Redis中,哈希类型是指键值本身又是一个键值对结构,形如value={{field1,value1},…{fieldN,valueN}}
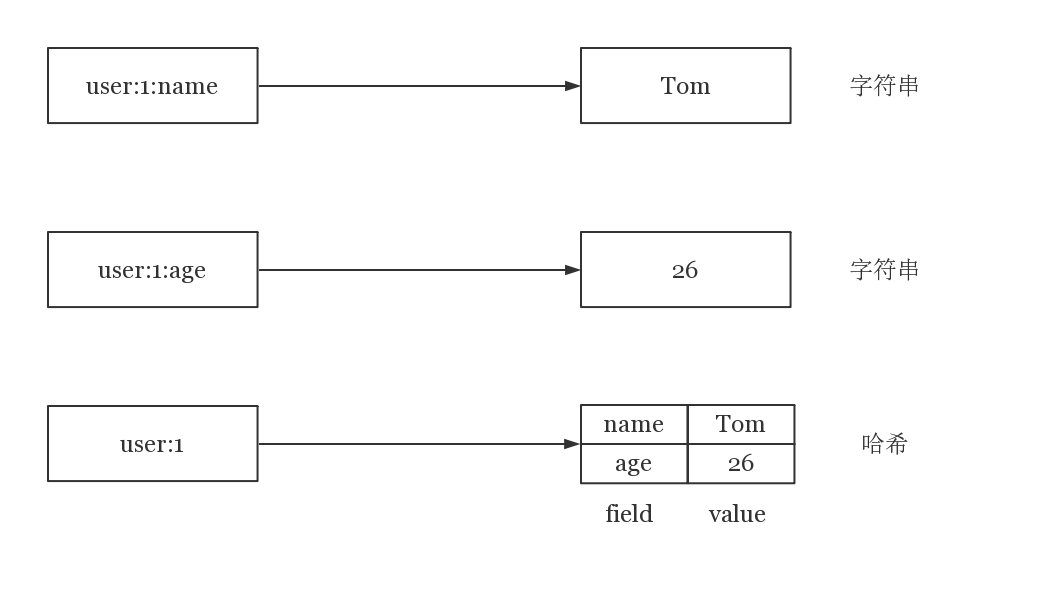
哈希类型中的映射关系叫作field-value,注意这里的value是指field对应的值,不是键对应的值,请注意value在不同上下文的作用。
设置值
hset key filed value
为key名为user:1设置field-value
127.0.0.1:6379> hset user:1 name Tom
(integer) 1
127.0.0.1:6379> hset user:1 age 26
(integer) 1
Redis额外提供了hsetnx命令;hset和hsetnx的关系与set和setnx的关系类似,如果没有则添加,如果有则不作操作,只不过hsetnx是对于field操作的,setnx是相对于key来做操作
获取值
hget key field
获取key为user:1,分别获取field为name和age的值
127.0.0.1:6379> hget user:1 name
"Tom"
127.0.0.1:6379> hget user:1 age
"26"
删除field
hdel key field [field ...]
删除key为user:1,field为sex的值;返回的是删除的个数
127.0.0.1:6379> hset user:1 sex male
(integer) 1
127.0.0.1:6379> hdel user:1 sex
(integer) 1
计算field个数
hlen key
获取key为user:1的field个数
127.0.0.1:6379> hlen user:1
(integer) 2
批量设置field-value
hmset key field value [field value ...]
批量设置key为user:2的field-value
127.0.0.1:6379> hmset user:2 name Jerry age 15
OK
批量获取field-value
hmget key field [field ...]
批量获取key为user:2的field为name和age的value
127.0.0.1:6379> hmget user:2 name age
1) "Jerry"
2) "15"
判断field是否存在
hexists key field
返回个数,没有就返回0
127.0.0.1:6379> hexists user:1 name
(integer) 1
127.0.0.1:6379> hexists user:1 job
(integer) 0
获取所有field
hkeys key
获取key为user:1的所有field
127.0.0.1:6379> hkeys user:1
1) "name"
2) "age"
获取所有value
hvals key
获取key为user:1的所有value
127.0.0.1:6379> hkeys user:1
1) "name"
2) "age"
获取所有的filed-value
hgetall key
获取key为user:1的所有filed-value
127.0.0.1:6379> hgetall user:1
1) "name"
2) "Tom"
3) "age"
4) "26"
使用hgetall时如果哈希元素过多,有可能造成Redis阻塞,尽量避免使用,可以用hscan命令渐进式遍历哈希类型
计数
增加指定数字
hincrby key field increment
给key为user:1,filed为age的value加5
127.0.0.1:6379> hget user:1 age
"26"
127.0.0.1:6379> hincrby user:1 age 5
(integer) 31
增加指定浮点数
hincrbyfloat key field increment
计算value的字符串长度
hstrlen key field
获取key为user:1,field为name的value长度
127.0.0.1:6379> hstrlen user:1 name
(integer) 3
内部编码
哈希类型的内部编码有两种:
– ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
– hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)