Redis客户端执行一条命令分为如下四个过程
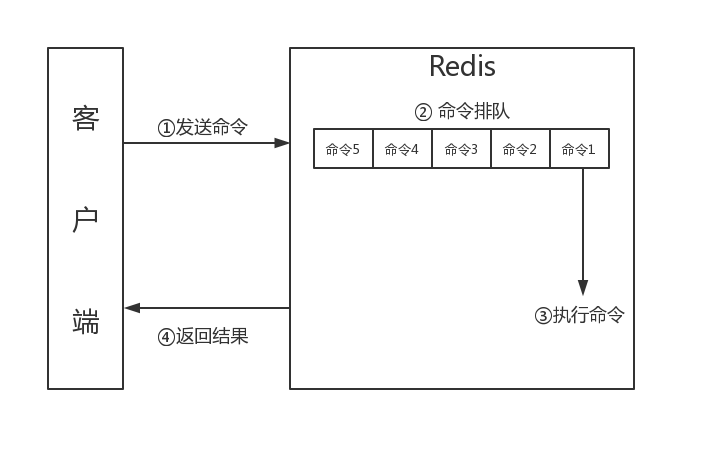
无论网络延如何延时,数据包总是能从客户端到达服务器,并从服务器返回数据回复客户端,这样的从1~4所需要的时间称为Round Trip Time(RTT,往返时间)
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT,但是大部分命令不支持批量操作,这样每次去请求在网络上消耗时间是非常不明智的,Pipeline(流水线)机制能改善上面这类问题,它能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端
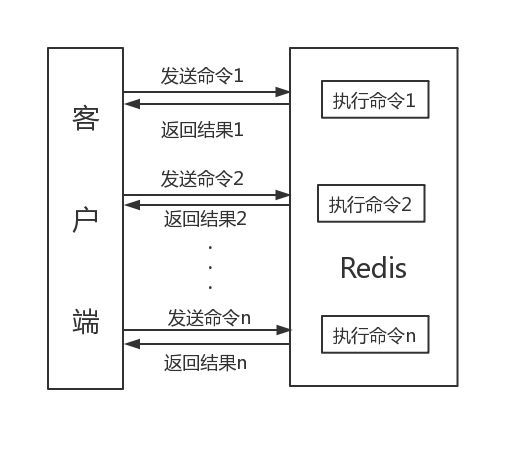
下图是不使用Pipeline的情况,请求多少次就会有多少RTT,会在网络传输上耗费大量的时间
Pipeline执行速度一般比逐条执行要快;客户端和服务端的网络延时越大,Pipeline的效果越明显,下图是使用pipeline执行的情况
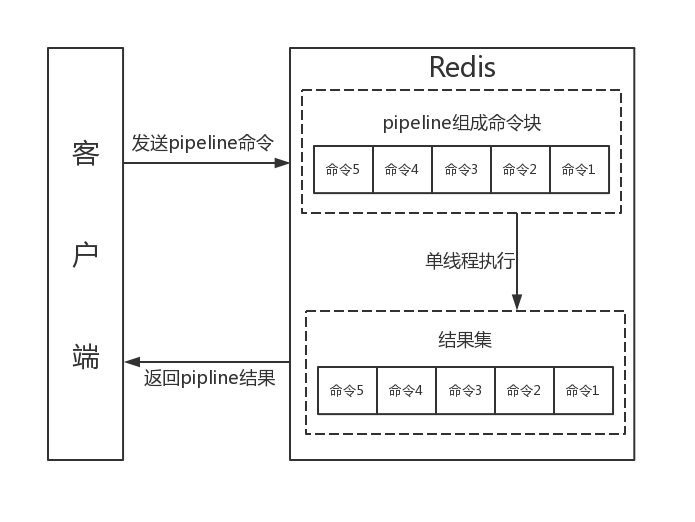
可以使用Pipeline模拟出批量操作的效果,但是在使用时要注意它与原生批量命令的区别,具体包含以下几点:
- 原生批量命令是原子的,Pipeline是非原子的
- 原生批量命令是一个命令对应多个key,Pipeline支持多个命令
- 原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户端的共同实现
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成。Pipeline只能操作一个Redis实例,但是即使在分布式Redis场景中,也可以作为批量操作的重要优化手段